Etnisch profileren met algoritmen
Written by Rob on februari 17, 2021

In deze blog leg ik uit hoe een algoritme werkt. Met deze aanwijzingen kun je het zelf proberen en bekijken wat je ervan vindt. Sommige dingen zijn een beetje technisch, maar laat dat je niet afschrikken.
Bezorgd over algoritmen
De afgelopen tijd denk ik veel na over algoritmen.
Want met algoritmen kun je etnisch profileren. Etnisch profileren wil zeggen: eerst personen selecteren op grond van hun nationaliteit of etnische afkomst en daarna het verband tussen de gevonden personen met een of andere vervelende kwestie onderzoeken.
Dat etnisch profileren kun je al wandelend of patrouillerend op straat doen, je combineert het uiterlijk van bepaalde mensen met je eigen ‘professionele’ onderbuikgevoel.
Maar het kan dus ook digitaal op basis van onzichtbare geregistreerde gegevens als nationaliteit, godsdienst of etniciteit. Dan heb je algoritmen nodig.
De wet
Volgens de wet moet de strafrechtelijke opsporing in Nederland zo werken: de politie onderzoekt een of andere strafbare kwestie, en brengt dan pas mensen in kaart, die ze redelijkerwijs daarvan kan verdenken, ongeacht hun nationaliteit of etniciteit.
Etnisch profileren is precies het omgekeerde: je gaat uit van de schuld van mensen met een bepaald kenmerk, je volgt ze, je vindt een probleem, en gaat over tot vervolging.
Ook het bedrijfsleven vindt het trouwens interessant om mensen te kunnen selecteren op grond van bijzondere kenmerken: huidskleur en afkomst zijn interessante aanknopingspunten voor gerichte marketing en reclame.
Kortom, veel mensen krijgen bij het woord algoritme tegenwoordig een vieze smaak in de mond.
Maar in het dagelijks leven gebruiken we heel vaak algoritmen, ook voor positieve of gewone doeleinden.
Algoritmen in Funda, Marktplaats en Booking
Stel, ik wil een huis kopen. Ik zoek bijvoorbeeld een woning met 3 kamers in Nijmegen tussen €100.000 en €150.000. Op de website van Funda staan alle huizen die in Nederland te koop zijn. Dat is fijn. Maar ik wil liever niet álle duizenden woningen vanaf Aalsmeer tot Zoutkamp doornemen.
De software van Funda bevat daarom algoritmen, filters, die ik zelf kan instellen. Door de algoritmen blijven alle goedkopere en duurdere woningen én die buiten Nijmegen buiten beeld. En binnen Nijmegen zie ik alleen de woningen met 3 kamers. Nu kan ik rustig mijn keuze bepalen.

Ook bij booking.com en Marktplaats werken ze met algoritmen. Lekker gemakkelijk dus.
Formules in Excel, het rekenprogramma
Naar aanleiding hiervan schoot me te binnen dat er een computerprogramma is waarmee ik zelf al veel algoritmen heb gemaakt. Dat is Excel. (Het wordt een beetje technisch, maar lees vooral verder.)
Je weet misschien dat je in Excel formules kunt ingeven die berekeningen maken. Een manier is om de getallen in een formule te zetten: = 8 + 3. Als je op return drukt, komt uitkomst van de som in het vakje. (Vergeet niet te beginnen met het =-teken.)
Gegevens in het juiste vakje
Het kan ook op een andere manier. Daarvoor zet ik elk getal in een in afzonderlijk vakje. Ik kan die getallen nu gebruiken in berekeningen zonder ze over te typen in een formule. Dat gaat zo.
Alle vakjes in een excel-werkblad hebben een unieke positie, bijvoorbeeld kolom A rij 1, en kolom L, rij 12, kortweg A1 en L12.
Probeer het zelf uit. Zet de getallen 5 en 2 in de vakjes A3 en B3. Zet de cursor in een leeg vakje, bijvoorbeeld C3. Typ nu deze formule: =A3 + B3. Dit zijn de namen van de vakjes waarin de getallen staan die je wilt optellen.

De uitkomst komt in het vakje C3. De uitkomst hangt af van welke getallen er in A3 en B3 staan. Het leuke is dat je die getallen kunt vervangen hoe je maar wilt. En de uitkomst in C3 verandert steeds mee.

Niet alleen met getallen, ook met tekstgegevens in vakjes kun je in Excel dingen doen.
Personen en gegevens selecteren
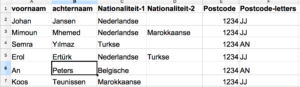
In mijn (fictieve) databestand heb ik heb ik zes personen. Van hen weet ik welke nationaliteiten ze hebben en in welk postcodegebied ze wonen. Alle gegevens staan in aparte vakjes. Ik ga er natuurlijk vanuit dat mijn gegevens kloppen.
De nationaliteiten van deze personen staan in de kolommen C en D. Voor Jansen staan ze in C2 en D2, d.w.z. kolom C rij 2 en kolom D rij 2, en voor M’hemed in C3 en D3 en zo verder.
Als je deze personen naloopt, zie je er een die alleen de Nederlandse nationaliteit heeft, twee met een dubbele nationaliteit en drie met alleen een niet-Nederlandse nationaliteit.
Het is veel te omslachtig om ze per persoon na te lopen. Ik wil een lijst maken met een selectie. Daarvoor gebruik ik een algoritme.
Begin met een vraag
Je begint een algoritme altijd met de vraag waarop het een antwoord moet geven.
Laat ik daarom dit vragen: welke personen in mijn bestand hebben de Nederlandse nationaliteit?
Deze vraag moet ik zo formuleren dat het algoritme “ja” of “nee” kan antwoorden. Meer kan een algoritme niet: een algoritme verifieert iets en het antwoord is dan telkens “ja” of “nee”.
Mijn algoritme verifieert de twee vakjes waarin de nationaliteiten staan.
De nationaliteiten staan immers in twee kolommen: C en D. Voor Jansen verifieert de formule de vakjes C2 en D2, dat wil zeggen: kolom C rij 2 en kolom D rij 2. Voor M’hemed kijkt het in C3 en D3 en zo verder.
Het algoritme verifieert beide kolommen en ALS in een van beide kolommen inderdaad “Nederlandse” staat, is de uitkomst in de betreffende rij “ja” (en anders “nee”).
Daarom schrijf ik in de formule “OF”. Dat betekent: zoek “Nederlandse” in kolom C OF in kolom D. Neem bij het overtypen van de formule de haakjes, de puntkomma’s en de aanhalingstekens precies zo over.

Aan de ja’s en nee’s kan ik in een oogopslag zien dat Jansen, M’hemed, en Ertürk de Nederlandse nationaliteit hebben en Yılmaz, Peters en Teunissen niet.

Etnisch profileren
Als etnisch profileerder ben ik vooral geïnteresseerd in Turken en Marokkanen. Die zijn immers qua etniciteit en cultuur ‘niet-westers’, ze zijn moslims en zo meer. Het maakt mij eigenlijk niet uit of ze nu wel of niet de Nederlandse nationaliteit hebben. Mijn professionele ‘onderbuikgevoel’ zegt mij …
Daarvoor stel ik een tweede onderzoeksvraag: Heeft betrokkene de Turkse of Marokkaanse nationaliteit?
Daarvoor maak ik algoritme nummer 2. De formule verifieert opnieuw de informatie in de kolommen C en D, nu met een andere vraag. Als in C OF D “Marokkaanse” OF “Turkse” staat, is het antwoord “ja”.

Hieronder zie je het antwoord op deze vraag, d.w.z. de uitkomst van dit algoritme:

Ik kan het algoritme niet op slechts twee verschillende nationaliteiten (Turks, Marokkaans) laten zoeken, maar op drie, vijf, tien of nog meer.
En in plaats van “ja” of “nee” in een nieuw vakje achter de naam te zetten, zoals in dit voorbeeld, kan ik het programma ook een compleet nieuwe lijst laten maken, waaruit alle gevallen met “nee” zijn weggelaten.
Gegevens combineren
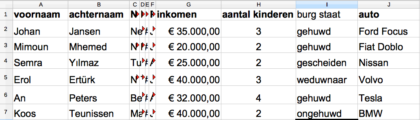
In het fictieve voorbeeldje hieronder heb ik informatie gezet die elke gemeente van haar burgers heeft (naam, aantal kinderen, burgerlijke staat, adres, enzovoort).
Ik heb extra informatie opgevraagd en gekregen van de Belastingdienst (inkomen) en de RDW (auto). Die heb ik erbij geplaatst.
Met deze gegevens kan ik als etnisch profileerder echt goed aan de slag.
Nationaliteit plus inkomen
Ik wil nu graag een formule maken, waarmee ik de Turkse en Marokkaanse burgers kan uitfilteren die een inkomen hebben van €25.000 of meer.
Voor dit algoritme moet ik de functie “EN” gebruiken, want er zijn immers twee voorwaarden die tegelijk van toepassing zijn: [1] de Marokkaanse of Turkse nationaliteit EN [2] het inkomen is gelijk aan of hoger dan €25.000. Als de beide voorwaarden waar zijn, komt er een verklarende tekst in het vakje en anders blijft het vakje leeg.
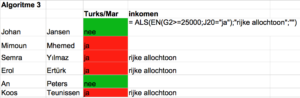
Het resultaat:
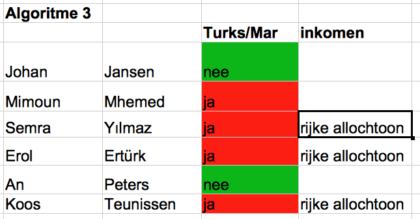
Je ziet dat M’hemed niet in het nieuwe rijtje terechtkomt, omdat hij een lager inkomen heeft dan €25.000. En An Peters en Johan Jansen staan niet in het nieuwe rijtje, omdat ze niet Turks of Marokkaans zijn.
Informatie afgeven
Gelukkig mogen de overheidsdiensten (RDW, belastingdienst, politie, GGD, enz.) hun gegevens (inkomen, auto, boetes) aan niemand zomaar afgeven, ook niet aan andere diensten (zoals de gemeente en het UWV).
Ook particuliere bedrijven die veel van mij weten, zoals FaceBook, mogen mijn privégegevens (foto’s, relaties, vriendschappen, politieke meningen, ip-adres) niet zomaar afstaan.
De politie kan ze alleen opvragen ten behoeve van een specifiek onderzoek. Tenminste …
Zijn algoritmen alleen slecht? Nee, ze zijn juist heel handig en inmiddels onmisbaar in onze samenleving.
Kunnen ze verkeerd gebruikt worden? Ja, dat kan! Je kunt ze namelijk combineren met je ‘professionele onderbuikgevoel’ over etnische minderheden …
De term algoritme is een Arabisch leenwoord: Algoritme verwijst naar de Perzische wiskundige Mohammad ibn Musa al-Khorizmi (780-845) (الخوارزمي) die leefde in Baghdad, maar schreef in het Arabisch. Hij was afkomstig uit Khorezm, vandaar zijn naam.
Anderzijds bestaat ook “positief etnisch profileren” – wanneer bedrijven naar diversiteit (ook in de top) streven en hierdoor gericht kans geven aan vrouwen en allochtonen (of allochtone vrouwen :)) in tweeërlei opzicht interessant fenomeen